Unlocking the Potential of Generative AI
This case study explores the implementation of an AI-enabled Support Assistant, highlighting:
- A real-world scenario where Generative AI enhances efficiency and reduces costs.
- Key technical insights, challenges, and innovative solutions.
- Future extensions and opportunities to further leverage Generative AI for evolving business needs.
Join us as we delve into the world of AI-powered support assistant and uncover the possibilities that await when technology meets innovation.
Background
At TechXSherpa, we recently collaborated with a prominent client in the Financial Accounting Automation sector to implement an advanced Generative AI solution. Our client, a significant presence in this industry, identified the need to elevate their support processes to uphold their business user experience standards. With the expansion of their platform features and information resources, they faced challenges in providing timely assistance from their Knowledge Repository, resulting in slowed customer support and bottlenecks for their team. Recognizing the opportunity for innovation and efficiency enhancement in their information retrieval processes, they opted to make significant improvements.
The objective was clear: empower their end-users with quick and accurate responses to their support queries while leveraging the wealth of knowledge contained within their internal repositories. To achieve this, they sought to integrate advanced AI technologies into their existing platform. By enabling users to independently address a significant portion of their queries, they aimed to reduce reliance on support engineers, thereby enhancing operational efficiency and potentially freeing up resources for more complex tasks.
The answer? An AI-powered Support Chat Assistant equipped with the ability to access the client's exclusive Knowledge Repository, available online. Utilizing Retrieval Augmented Generation (RAG) technology, this assistant merges the functionalities of information retrieval systems with generative AI, guaranteeing responses that are not just precise but also customized to meet the distinct needs and context of their users.
Objectives
The key goals of our collaboration with the client were to:
- Enhance the User Experience:
- Offer prompt responses to queries and searches, minimizing the requirement for external assistance wherever feasible.
- Ensure responses are backed by evidence and reference sources.
- Enhance user engagement through a more intuitive, contextually aware and conversational approach.
- Increase the Operational Efficiency:
- Freeing up resources that could be redirected towards handling more complex tasks and improving overall productivity within the organization.
- Provide a single access point to efficient information retrieval.
- Leverage the Internal Knowledge:
- Bridge the fragmented information silos and encourage knowledge sharing.
- Enhance content discoverability through improved indexing and tagging mechanisms.
- Drive Business growth:
- Improve Customer satisfaction via efficient support services.
- Reduce operational expenses.
Solution
To achieve these objectives, the client, working closely with TechXSherpa, opted to deploy an AI-powered Chatbot utilizing RAG (Retrieval-Augmented Generation). RAG is an advanced AI framework and technique in natural language processing that combines elements of both retrieval-based and generation-based approaches . Its primary goal is to elevate the quality and relevance of generated text from the model by integrating information retrieved from a knowledge base, thereby unlocking the enterprise wisdom. By incorporating this technique, chatbots can deliver efficient and effective responses.
Integrating retrieved information into the response generation process ensures the chatbot reliance on factual data from the retrieval source, thereby minimizing the risk of providing false or misleading answers.
Through the Chatbot, users can conduct semantic searches within the organization's knowledge base via an intuitive and contextually aware chat interface. Each response provided by the Chatbot is backed by evidence from a reference source. Additionally, this capability lays the groundwork for future expansion to support multiple languages, thereby extending its reach to an even broader audience.
The following simplistic image illustrates how RAG based Chatbots provide responses to user queries by combining search/retrieval and natural language generation techniques.

Retrieval systems specialize in locating pertinent information within extensive datasets, while generation models excel at crafting natural language text. RAG, by integrating these two components, endeavours to generate responses or text with exceptional accuracy and contextual relevance. This approach proves invaluable across various tasks, including question answering, document summarization, and chatbot applications
RAG serves as a pragmatic remedy for the constraints observed in current LLMs, such as static knowledge, domain-specific expertise gaps, and the risk of generating erroneous responses or hallucinations. This method encompasses a wide range of use cases, circumventing the need for alternatives like Fine-Tuning or Training LLMs, which are both resource-intensive and costly. These alternatives should only be considered when RAG proves inadequate.
Now, let's explore the technical implementation in more detail.
Implmentation Overview
The overall solution can be categorized into the following key Modules:
- Crawler: The crawler crawls the client’s knowledgebase web repository pages, scrapes the textual content, and persists this scraped content on a preconfigured S3 bucket on AWS Cloud.
- Ingestion Pipeline: The job of the Data Ingestion pipelines is as follows:
- Load the data documents - from S3 bucket with scraped content in our case.
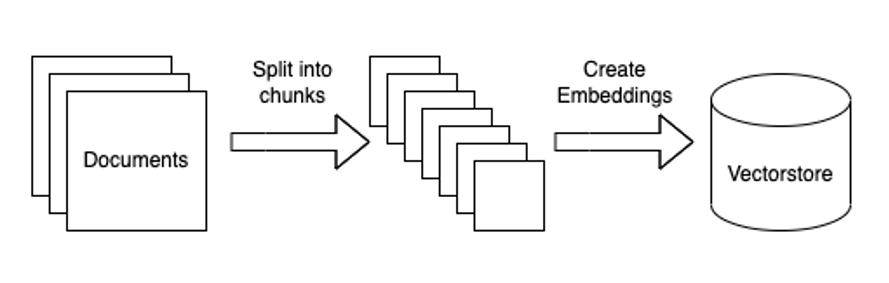
- Pre-process the documents - Any transformations, splitting/chunking and embedding the chunks in preparation for storage in a Vector Database.
- Storage & Indexing – Persisting & indexing the generated embeddings in a vector database for efficient matching & retrieval against the user queries. The following diagram illustrates the flow in the ingestion pipeline:
- A Chat UI widget: Implemented via a ReactJS component, leveraging SDK & libraries from Sendbird 3rd party partner to be eventually integrated on the client's existing website. The Chat UI will enable the conversation between the client's authenticated end-users and the Chatbot Assistant (described below).
- Chat-Bot: The Chatbot will be the module responsible for addressing the end-user's queries overall. The Bot will have the following integrations:
- Sendbird: The Bot will expose a webhook endpoint to Sendbird for receiving user messages/queries directed to the Bot. The Bot will also push its response messages to the users by leveraging Sendbirds' appropriate APIs.
- Vector database: To match users' queries with the saved embeddings and retrieve only relevant data to be eventually passed to the LLM along with the user query for a relevant response.
- OpenAI: The Bot will leverage the LangChain framework and the models from OpenAI for embedding (text-embedding-ada-002) and generating LLM (apt version of GPT-4) responses.
The following is a high-level representation of the overall communication flow:

Technology Stack
Our RAG based AI Chat Assistant solution has been built by leveraging the following:
- Python FastAPI web framework.
- Scrapy framework for web crawling & scraping.
- LangChain framework used for constructing LLM powered applications.
- LangSmith for testing, debugging & monitoring LLM interactions.
- OpenAI Models
- ‘text-embedding-ada-002’ embedding model from Open AI.
- GPT- 4 LLM
- Storage
- Pinecone Serverless: High-dimensional vector database for storing and querying embeddings needed for data augmentation with LLM.
- Client-Server Communication
- SendBird as a 3rd party chat solution provider.
- AWS for cloud solutions:
- S3: Object storage service for storing the crawled data JSON file.
- ECR: Elastic Container Registry for Crawler Docker container image.
- Lambda: Serverless compute service for executing Crawler code.
- Event Bridge: Serverless event bus for triggering Lambda functions at a scheduled frequency.
- Elastic Beanstalk: Platform as a Service (PaaS) for deploying and scaling web applications: leveraged for Chat & Ingestion modules.
- Containerization Docker
Challenges
Throughout the exploration and implementation phases, there were numerous iterations of designs, validations, and adjustments. Below are some challenges encountered and successfully addressed during the development process:
- Recursively crawling the knowledgebase data, detecting failures & building retry mechanisms.
- Deciding the right chunking strategy for data to be vectorized for efficient retrieval.
- Iterative Prompt engineering to reduce hallucinations and contain the responses in the domain.
- Updating Vector database without any downtime when new data is discovered after crawling & scraping.
- Ensuring the reference citations are accurate.
- Reducing the complexity of state management due to the necessity of maintaining conversation history for effective response handling.
- The LLM responses take time which can’t be avoided but we built mechanisms like reducing any additional processing latency and planning for accommodating streams to mitigate the challenge.
Achievements & Way Forward
The Agent (currently in the design phase) will also be furnished with a persistent short-term and long-term memory to store internal logs, such as past thoughts, actions, and observations. Once completed, this enhanced solution will enable users to:
- Obtain answers to their support queries based on the data from the knowledgebase.
- Access their data conversationally, including due invoices, pending reconciliations, and expense management workflow execution.
The solution has shown remarkable results in recent internal evaluations and is currently undergoing enhancements to incorporate additional functionality.
In the forthcoming upgraded version, business users will gain the additional capability to interact with their specific data in a conversational manner, rather than navigating through traditional UI flows. The team is actively developing this new version using AI Agentic Flows, where an Agent is equipped with multiple tools and leverages LLM to determine the appropriate tool to invoke, the sequence in which they should be called, and the number of times, before returning the final results to the end user query.
Conclusion
In conclusion, the ongoing evaluations of the implementation of the AI Support Chat Assistant are showing promising results, indicating potential improvements in user experience, operational efficiency, and knowledge utilization for our client in the Financial Accounting automation sector. As we continue to refine and enhance the solution, we anticipate even greater benefits and advancements in support services for our client, further solidifying their position as a leader in the industry.
For any inquiries, discussions, or demonstrations, please don't hesitate to reach out to us at info@techxsherpa.com